Automated requirement coverage calculation and its visualization in Allure Framework
Do you want to know how to turn the requirement coverage metric into an actual linter for your codebase? Read more to find out! This is a case study about an automated pipeline with that metric.
Automated requirement coverage calculation and its visualization in Allure Framework
Let's talk about requirements coverage. It is a somewhat tricky topic: if we want to cover something, it should be countable and modular. When calculating code coverage, there's no problem - you're counting lines of executed code.
Requirements, on the other hand, come in varying formats, usually tied to a particular system, like TestRail. So, if you're not into a particular system or if your teams use several different systems, you might get an apples-and-oranges situation when trying to count requirements.
In this article, I'd like to tell you about a solution to this problem developed at my former company. The testing process there was fully automated, with manual tests being run only occasionally. The requirement coverage metric helped the company maintain a pipeline with automated quality gates.
Below, we'll first talk about the general approach and then about its implementation with PyTest and Allure Report.
The approach
We define a requirement as an artifact to which an automated test can be mapped. Having a corresponding automated test for each requirement provides important advantages:
- We always know if a requirement is tested
- We always know what a particular test is doing
- It's trivial to calculate coverage
Our approach is fairly universal, and it can be used not just with requirements but also with manual test cases or user stories written by analysts - anything to which you can map a test.
The coverage metric we derive can be used by the engineers, managers, and analysts to track automation and set targets based on it. The metric is also used for automated checks.
Specifying requirements
There are several ways of specifying requirements:
- Jira. We can use tools like X-Ray or similar extensions to manage test cases and their relationship to requirements.
- Confluence. Here, requirement coverage is usually calculated using external tools.
- Text files. An increasingly popular option is to store requirements or use cases directly in the project repository as text files (.rst, .md, etc.). In this case, we can't rely on out-of-the-box solutions since a reporter like Allure has no direct access to the requirements.

At the company where this approach was implemented, development was carried out by several independent teams, and each team preferred its own format for storing requirements. As a result, there was no unified solution for calculating coverage for all teams.
In each of the above cases, the automated test must be linked to the related requirement. This can be done with a Jira issue ID, a link to a Confluence page, or a path to a file with the requirement.
Linking automated tests and requirements is very useful. Consider these situations:
- A programmer sees that an automated test has failed, and they need to figure out what that test was doing. It's a big help if there is a link to the requirement in the test: the developer pretty much has a high-level description of the test on hand.
- A new tester joins the team, and they've got to get acquainted with the project. They usually start with studying the code, and it's easier to do if the tests have links to requirements.
Calculating coverage
The process of calculating coverage is fairly simple. Once we've got data on automated tests and requirements, we've got to relate them to each other. Ideally, requirements should be mapped to tests in a 1:1 relationship. In reality, other situations are possible:
- Requirements that are not related to automated tests are considered not covered.
- Automated tests that are not related to requirements should be reviewed. Perhaps a requirement was forgotten? Or maybe the automated test is doing something strange and unnecessary? Or somebody just forgot to delete the test after its requirement was deleted?
- If multiple tests cover a requirement, we should review the tests or the requirement.
- It is possible that one automated test covers several requirements. For instance, setting up the test could be resource-costly, so it might be feasible to do it just once for multiple requirements. That is acceptable, and the test will count towards covering both requirements.
Ensuring requirements are atomic
To ensure the 1:1 relationship between requirements and tests, requirements must be sufficiently atomic. If the requirement is too broad (e.g., "ensure that the user can log in"), it might need many tests to be fully covered. However, the presence of even one test would still show full coverage, which would be misleading.
This means that our requirements are more granular than traditional business requirements. We define a requirement as something onto which you can map an automated test.
Ensuring that requirements are atomic is done collectively. Some of the requirements are written by automation engineers, while others are handed to them by developers and analysts. Those requirements that can't be automated are separated and are not tracked when calculating coverage.
When we introduced the system, we had to spend some time restructuring our requirements and removing mismatches with automated tests. It has taken some work, but in the long run, it paid off.
Visualizing the results with Allure Framework
Visualizing results is a slightly more complicated process than generating them. The problem is that if we sent the data to Confluence or Grafana for visualization, we would create a whole new layer of entities that must be maintained. We would constantly mess around with scripts that would collect test data for those systems. Also, showing coverage of requirements for a specific repository branch would be problematic with this approach.
We decided to combine the test execution report and coverage calculation. Because we use Allure Framework for both, we do not need to introduce any new layers to the tech stack.
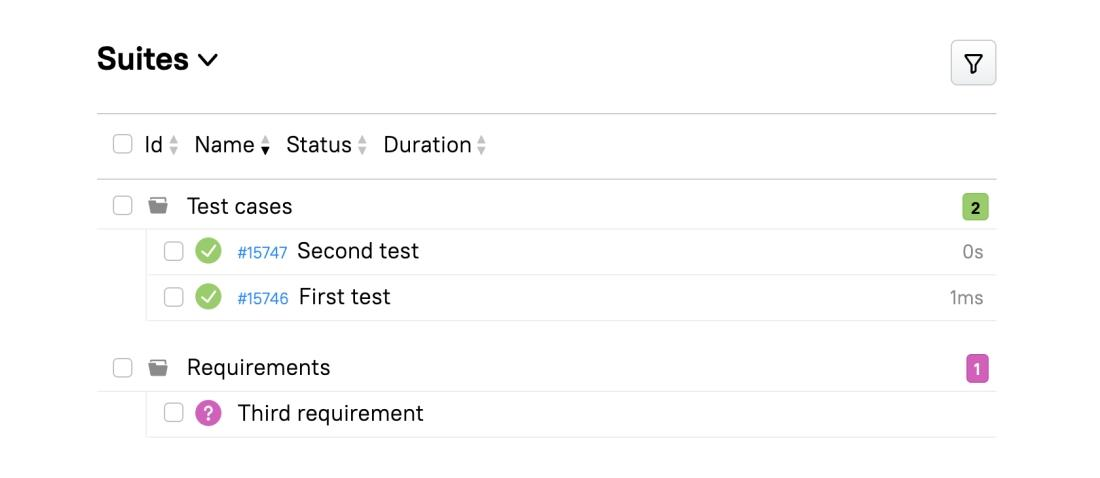
We represent requirements as fake empty tests with a link to the requirement source (Jira, Confluence, or text file). If a requirement is covered with an automated test, we show the actual test; if it isn't, we show the fake test. Here’s how it looks:
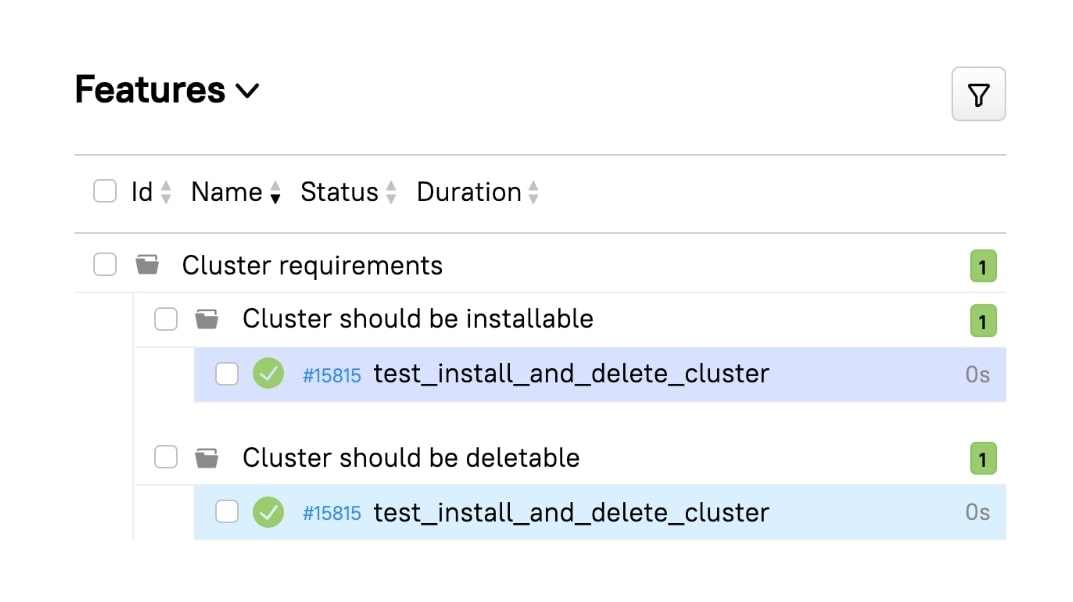
If a test covers multiple requirements, it is shown correctly for each requirement:
At this point, we realized that we could now display tests in the same structure as written requirements:
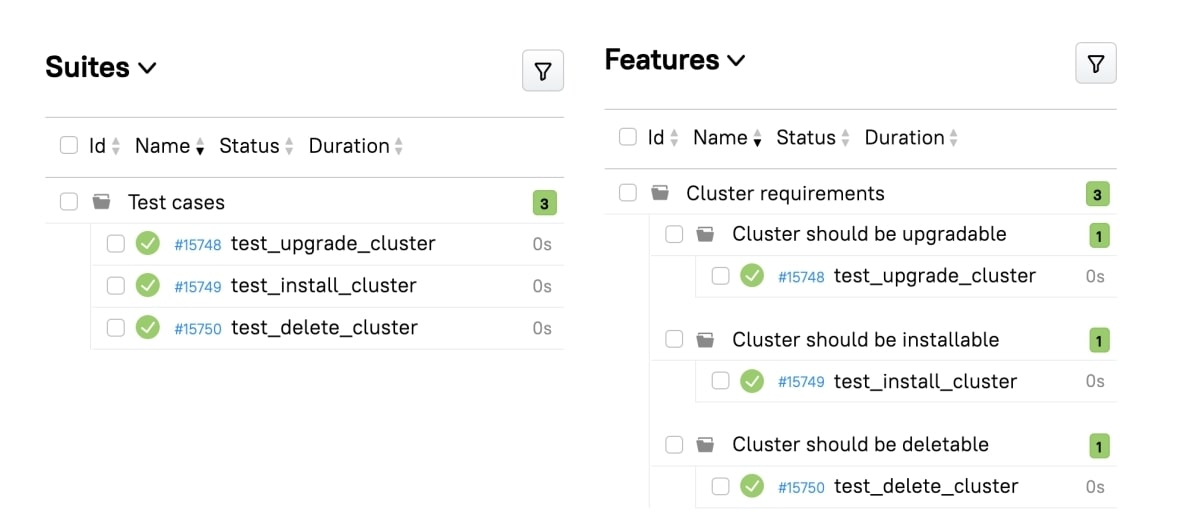
Moreover, we wouldn't need to add any extra annotations to the tests for that to work - just a link to the requirement:

All extra code for the automated test would then be generated on its own. Any tests without linked requirements would be shown as a flat list outside the requirement hierarchy.
Partial test runs
What if we have to calculate coverage when some tests are present but not executed? In this situation, it would be wrong to consider the related requirements not covered at all. However, it is also necessary to convey to the user that automated tests for certain requirements have not been run.
We decided to generate the "skipped" result for such requirements and add the names of the tests that were not run to their descriptions.
Version control
An important advantage of our approach is that it can be used with a version control system, and we can calculate coverage for each branch of code.
It looks something like this: "Hey, Alice wrote new tests; we can see she covered some requirements! Let's merge!" Or: "Bob wrote so many new requirements! We won't merge until everything is automated!"
Linter
The teams can monitor the coverage metric directly, but it can also be used to perform automated checks. We've started using requirement coverage as a linter, adopting the same approach as with code coverage: if the metric is below a certain percentage or if the tests refer to a non-existent requirement, we don't even run the automated tests:

This situation is treated like a typo in the code - the test will fail, and the developer will see the error and fix it. That can happen automatically, e.g., during a pull request; in this case, we have an automated quality gate.
The PyTest plugin
As I've mentioned, our approach is rather general and can be used with different tech stacks. Both Allure Framework and Allure TestOps can be used for reporting and calculating coverage. The trick is to produce the entities that will represent requirements.
In our case, we achieve this with my PyTest plugin, but it's also possible to use a Java testing framework or something else.
The plugin structure
Most test frameworks consist of three components:
- A collector that gathers tests and various metadata about them.
- A runner that runs the tests obtained from the collector.
- A reporter that generates a report in some form based on the results from the runner. In our case, we used Allure Framework for this function.
The collector is a simple abstract class with a 'collect' method that returns a list of requirements. Because of this, our plugin can work with different collectors. When PyTest is launched, the name of the collector is passed as an argument:

That means that our plugin can be used with different tech stacks.
The process
To calculate coverage, we need to get information about the existing tests, but the result of their execution is not important to us. PyTest provides this information in the form of hooks. We can get a list of tests that will be run, a list of unselected tests, and labels where we will store the test identifier, the test file name, and the test function name - all of this without actually running the tests.
Next, we need to get the requirement objects, and once we have them, we can sort requirements with and without tests into different piles. Finally, we calculate coverage.
Presenting the results
The results now need to be reported. The easy way of doing it is just writing a pretty string with the coverage figure directly to the console:
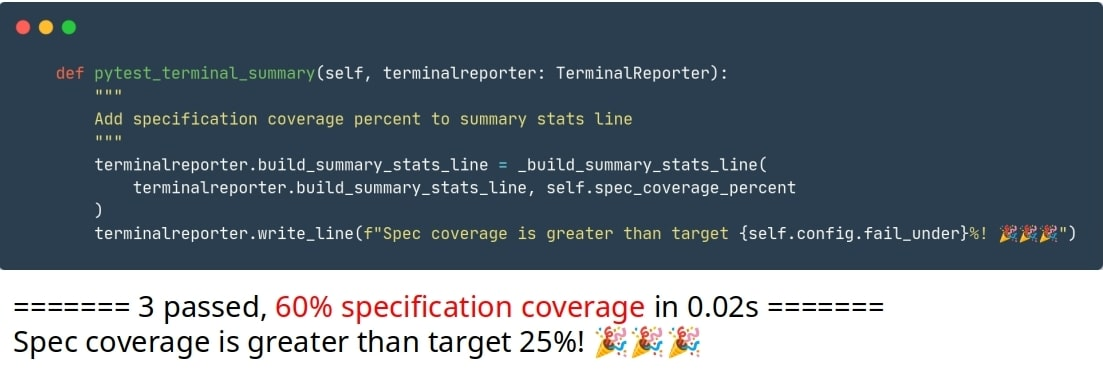
The more thorough way is using Allure. Naturally, integration with Allure is different in each framework. What we need is to get the Allure reporter object and add new entities through it that are normally added during the test life cycle.
- In Java frameworks, this is done quite easily - through the lifecycle, which can be easily obtained anytime during the test.
- In PyTest, it's slightly more complicated. First, we need to find a PyTest plugin called AllureReporter in the list of plugins. Then, we generate the fake tests that serve as requirements, set their status, and write info from the requirements into them.
Summary
To summarize, here are the main benefits that we got from adopting automated requirement coverage calculation:
- automated tests are linked to requirements
- automated tests that cover multiple requirements are displayed correctly
- coverage can be calculated for each branch of code
- coverage can be calculated for partial test runs
- a linter based on coverage prevents future difficulties
With this story, I wanted to convey the idea that this kind of automation is not difficult and allows you to delve into how your framework is structured internally. Test automation is not limited to writing tests. Work on developing new tools and studying your framework. Often, a difficult task is solved with a very small development effort; you just have to know what possibilities you have for this.