Managing Test Cases the TestOps way. Goodbye, folders!
Storing and reporting data from a large system to a human-readable format is a long-time-ago solved issue. Today, we will discuss Test Case Management and Testing, and the first question is “How do people usually store the test cases?”.

Managing Test Cases the TestOps way. Goodbye, folders!
Storing and reporting data from a large system to a human-readable format is a long-time-ago solved issue. “The Folders Tree” has won the battle in most cases. Folders in OS feel like riding a bicycle for most users. It is also a default UI/UX solution for storing and ordering data. Today, we will discuss Test Case Management and Testing, and the first question is: “How do people usually store the test cases?”
Right, in folders! It is definitely the default solution. But is it good enough to stay with us? We ask this question because most modern systems that require frequent and diverse access to data and information don’t store it in folders, e.g. Gmail, JIRA, Grafana, and Allure TestOps. Let’s try to find out why.
The Tree
Keeping test cases in folders is a well-established approach to store and manage tests. Testers are taught to follow this method and there are dozens of best practice pieces available giving advice on how to manage these folder structures. This approach provides an opportunity to think through and create the whole testing structure from the very start i.e. a QA manager can create folders for each page/feature of a web service at the outset – and therein lies the Tree.

You have your first tree and everything seems fine
It’s quite handy as the solution provides the whole scope. It allows for the estimation of testing coverage and results in an elegant testing model, filled with tests ordered by areas of responsibility. Looks good!
The Question
So, what’s wrong?
Imagine a beautiful web service thoroughly covered by automated and manual tests stored in folders (one folder per page). Sounds good but, in time, the testing team will be asked to make reports based on features or components. Creating these reports will require drilling down to the depths of the testing structure tree and remapping tests from folders to, say, features. Each new report will drain the precious efforts of the team as the delivery of the report takes up more and more time. If there are 200+ tests, it may take longer than one or two days, but what happens if there are 1000+ tests?
At scale, the Tree will demand team subtrees and policies. Then, as soon as a new cross-section of data or tag to report pops up, complex team management issues arise. Testers won’t go to the neighboring subtrees to fix all the tests for various reasons. Another pitfall awaits those teams that combine manual and automated tests via several technologies, Java stores the tests by a class full name while JavaScript or Python use the package name only. This means that each framework will try to force its structure into the Tree, but in the end, it will become unbalanced and nonuniform as robots don’t follow one out-of-the-box pattern. Each one wants some attention and integration.

Robots don’t follow the same pattern out-of-the-box. Each one wants some attention and integration.
These changes always lead to a huge mess and the original structure becoming obsolete. As the project grows, teams then start considering moving from one storing criteria to another, however, going from a folder-per-page to a folder-per-feature approach has a huge overhead. Such changes to the test case management structure require complex refactoring of the whole Tree. The Head of QA with system analytics will need to rearrange the structure from scratch, balancing features and teams among new subtrees and branches. Then all the tests need to be migrated with great precision. It takes a lot of time and effort, and you are a lucky devil if you know nothing about this process!
Ops people have already solved it. How?
So let’s take a look at how Ops people solved the task to build various real-time reports. Site Reliability Engineers (SRE) and admins do love metrics, a lot! The reason is simple, a business always wants to know the service is down before users do. The story started with a classic hierarchical structure: data-center → cluster → machine → metrics (CPU, RAM, storage, etc.). Looks easy and obvious until the moment the team will need a dozen end-to-end metrics.
Imagine that you need a cross-cutting report about the load of all the machines that run a specific microservice. Building one with a non-labeled hierarchical structure is a challenging task, as it’s necessary to go through all the machines and filter those that run the exact microservice we need. It’s a hard-to-automate and algorithmically suboptimal solution. So, we need to add tags and attributes to all our objects. As soon as we do it, we can automate the solution. As we automate it, we need to optimize it. And the best way to optimize is to abandon the Tree for some plain tagged structure.
In the end, there is a plain pool of tagged objects. Any sorting, filtering, or grouping criteria, be it status, location, team, service, component, or feature, becomes a tag.
This approach allows you to run multiple graphs and reports without any additional overhead. You can make a query with your criteria and grouping rules e.g. ‘CPU load on machines running this microservice grouped by clusters’ and then the good news is that getting another report structure is as easy as the first one, just make another query like ‘Clusters load grouped by location’ and this will automatically rebuild and create a new rebalanced Tree. Think about large-scale services, SRE rooms have lots of screens with automated alerting for dozens of metrics grouped by multiple attributes. Can we create something like this in testing?
Do we need this in Testing?
Yes, we do. In the modern world, for each release, time-to-market is vital and development, security, and operations try to increase their pace by becoming agile. Shorter iterations and automation of code-review-test-build-deploy is fine for these departments. Against this background, testing often looks out of date with longer iterations, manual testing that takes days to run, a “waterfall” approach that pushes thorough testing out of the pipeline.
But faster releases need faster testing. To keep the pace of testing, teams come to shift right testing and test less practices.
But what if we need to keep testing as much as possible while staying within DevOps culture? What if we want to bring value by testing stuff?
Automate it! Automate report generation and make the original data storage as neutral to queries as possible so that anyone has an opportunity to get data from your test runs. Don’t create a structure at the start — gather indicators (test results), information (test cases and steps), and metadata (tags, signs) in the testing infrastructure and provide a fast and flexible way to view it.
Testers might need to manage tests by features, Developers by classes, and Managers by teams. This is how Allure TestOps can build different Tree views in a couple of clicks:
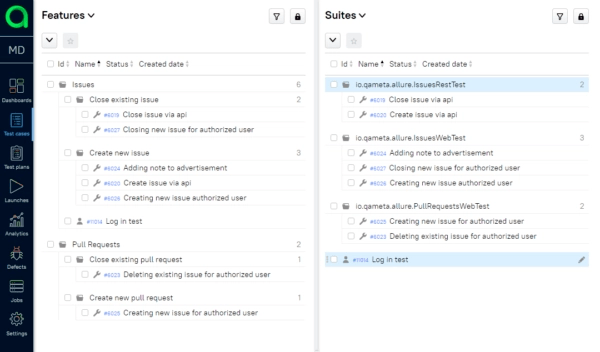
Some say that you can build a tag system for tests stored in folders, and it is possible, but it’s not common. Once the folder structure is created, it puts the main focus on itself and makes cross-sections secondary.
The truth is testing works with metrics just as monitoring in the example above. There may be a lot of metrics. And nobody knows in advance which reports will be necessary. However, creating a full and comprehensive list of metrics and tags is an actionable task. Such a system will provide all the data to create custom, fast and functional reporting without any static tree overhead.
The best example here is Atlassian JIRA. It allows for all sorts of real-time filtering, sorting, and grouping of tickets by any field.
Now, imagine the JIRA ticket management flexibility applied to test cases. Yes, the original Tree is not needed anymore as you may build one in seconds. That is a way to do TestOps in a DevOps-driven world.
Learn more about Allure tools
Learn more about Allure Report, our open-source testing reporting tool, or Allure TestOps, the all-in-one quality management platform.
Subscribe to our Twitter feed and GitHub Discussions, it is a wholesome place to get help and stay up to date with news.