Complete TestOps Guide
In this article, we will go over all the stages of a QA team's evolution on the way to TestOps, from a startup to an enterprise. We will try to cover goals, blockers, and tools for each stage.
Complete TestOps Guide
As we all know, DevOps is not a person — it's a complex set of processes, skills, communication, and tools between developers, ops, testing, and business units. DevOps entered the tech big scene several years ago with The Phoenix Project (2013) and The DevOps Handbook (2016) to address scalability issues and provide an opportunity for tech companies to ship software faster. It focuses on closing the loop between development and operations and drives production through continuous development, integration, testing, monitoring and feedback, delivery, and deployment.
The technology leaders have now switched to it, breaking communication barriers between dev and ops silos and reducing new features’ time-to-market. DevOps is responsible for the fact that we all use CI/CD systems, virtualization tools, and various automation to ship updates twice a day.
As always, the path to the current condition has not been an easy one. Whole areas of software development have struggled to keep up with the new pace: security, infrastructure, and, of course, testing. That is how DevSecOps, NetOps, and, eventually, TestOps evolved.
So what is TestOps, and why do we need it?
TestOps, being a subset of DevOps focused on testing, is basically a set of technologies and approaches that allows full transparency and controllability of all testing (not just QA) in a project. Here is why we need a new somethingOps for this.
Ten years ago, releases were large and rare. First, the code was written, then it was built and tested. The discovery of a bug at a late stage could lead to global refactoring or even delay the release. And over time, the market was led by companies who learned how to release faster.
The answer to the development cycle acceleration was DevOps and Agile. Both approaches focused on decomposing a large release: pipelines became more complex; quality gates appeared; the code of each microservice was thoroughly covered by unit and integration tests; releases were tested on canary releases. Each set of tests turned into a decision point: tests passed; tests failed, but we can ship in production; tests failed, and we have to roll back.
The problem is that the results of several types of testing (web, API, canary) on different frameworks and programming languages which are reproduced on several CI systems will be completely disjointed. They need to be interpreted, aggregated, and collected in one place to make a decision. The next step is to unify access to running, restarting, monitoring, and managing the whole zoo of tests in a single place.
That's what TestOps is: automated, transparent, accessible, and manageable testing across the entire DevOps pipeline. Do we have the proper tools for that?
What does DevOps-native testing look like?
Let’s imagine a team that builds an app. The app has a frontend, a backend, and a mobile version — each part is developed by a dedicated team. So how does each Dream Team work? Usually, there are 10+ people on a team; let's look at the typical roles found in such teams. Each role may be represented by several team members.
- Developers, responsible for writing code, refactoring, and pull-requests management.
- A project manager, responsible for the development schedule and Agile flow.
- A QA engineer, responsible for release testing and final product quality.
- An automation testing engineer (AQA engineer), their job is to drive testing automation to its limits.
- Ops person / Administrator, responsible for quality gates and pipeline maintenance.
So, how does testing work in such a team? A lot of collaboration opportunities open within such a flow. Here are the main tasks for the automation tester in DevOps:
- First of all, our automation testing engineer covers backend, frontend, and integration protocols with native automated tests. Native, in this context, means that the test uses the same tech stack as the code being tested. It also allows storing the tests in the same repository as the code. Since it’s a single repo, the developer is usually eager to help the AQA engineer with the code review and complicated tests’ development.
- The QA manager has an opportunity to review all the tests at the pull request stage: check customer scenarios and corner cases coverage, how many tests have been developed, and so on.
- In return, the AQA engineer checks the developers’ tests (unit and integration tests) from the QA point of view.
- The automation testing engineer is also responsible for the testing infrastructure. Of course, the low-level maintenance (like Docker or Kubernetes configuration, build scripts, or the testing environment setup) still stays with the Ops people. But configuring Selenium grids, browsers, or database data management stays with the automation testing people.
Okay, but why do we need dedicated QA people if the AQA is a tester already? While the automation tester works on low-level testing and quality, the QA person oversees the release management process.
- The first area of manual QA expertise in TestOps is actually decision-making with the project manager:
- What is being tested and what’s not? Coverage analytics and securing the releases with the AQA engineer.
- What bugs did we find, and how critical are they?
- Can we ship the release with current testing results or not?
- The other thing is cross-team communication for large-scale features. The QA manager advises the engineering team to cover specific use cases and cross-team APIs with tests.
- Exploratory testing. Something that will stay manual for a long time: while the regression testing and validation suites will be 100% automated, many unscripted tests must be executed on a release. Usually, these are new complex features testing that will be automated in the next sprints.
What about the flow?
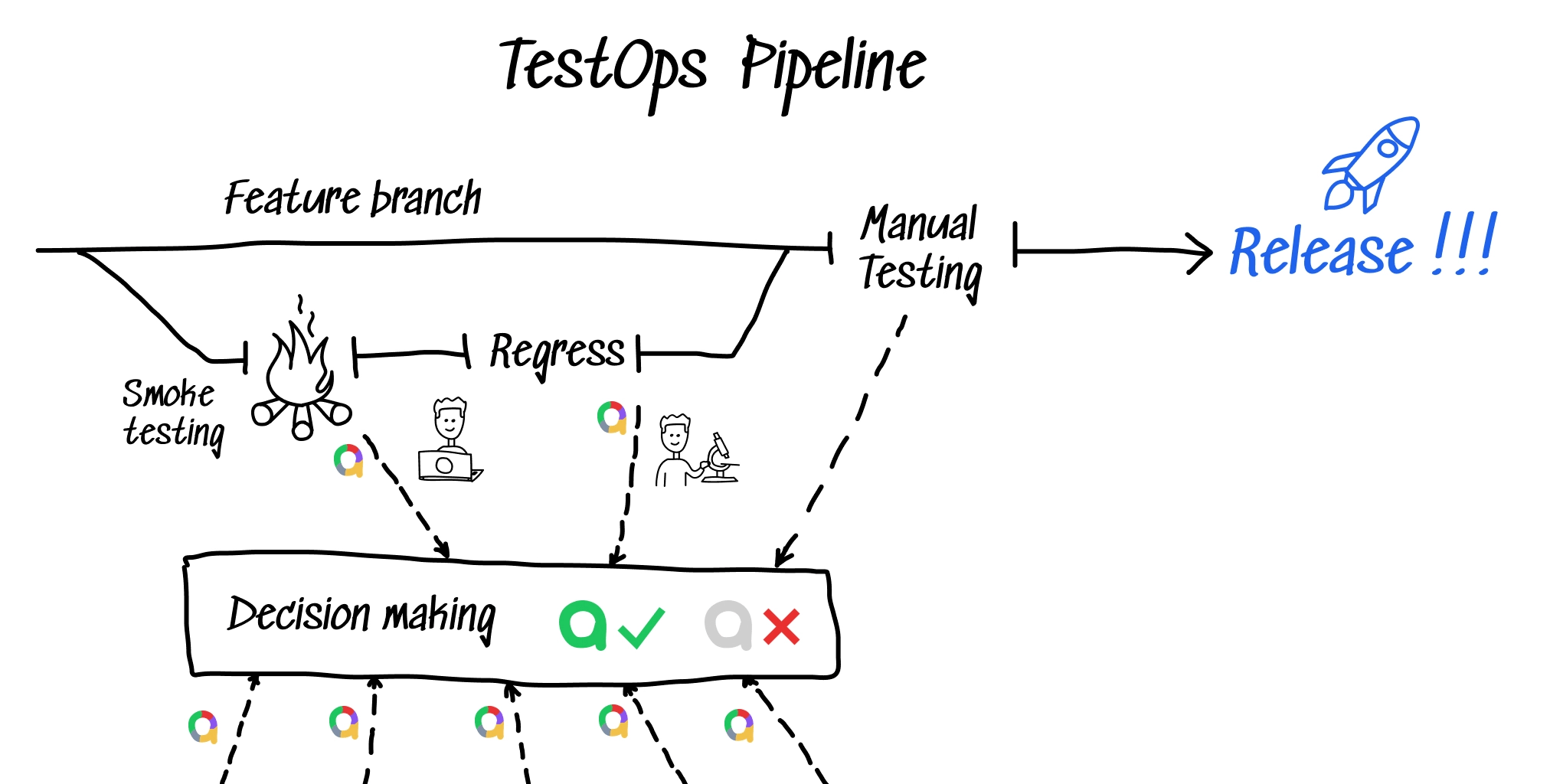
This all sounds good, but how does it work? Let’s take a look at an example of a whole flow, and its pros and cons:
- A developer creates a new feature branch, and when the job’s done, they have a pull request with some brand new code and a bunch of automated tests.
- AQA engineer reviews the PR and adds some more tests if necessary. Developers often test only the happy path and don’t care much about writing thorough tests with dozens of parameters and variations.
- After that, a QA manager starts the final testing review from the business point of view: which product requirements are covered with tests. The QA manager does not care about which exact tests are run; he thinks of the features and user stories coverage. Of course, they have a couple of checklists. Just to be sure, everything is tested, right?
- If the tests run green, the branch gets merged. If not, the team fixes the issue and goes back to step 2. At this point, each bug gets linked to an issue to be added to the regression run next time.
- All the testing on the pipeline allows us to automate testing documentation and analytics generation. Moreover, most tests are automated, so the expected testing duration is easily predictable.
This looks like a dream team, right? But how do we get there?
TestOps lifecycle
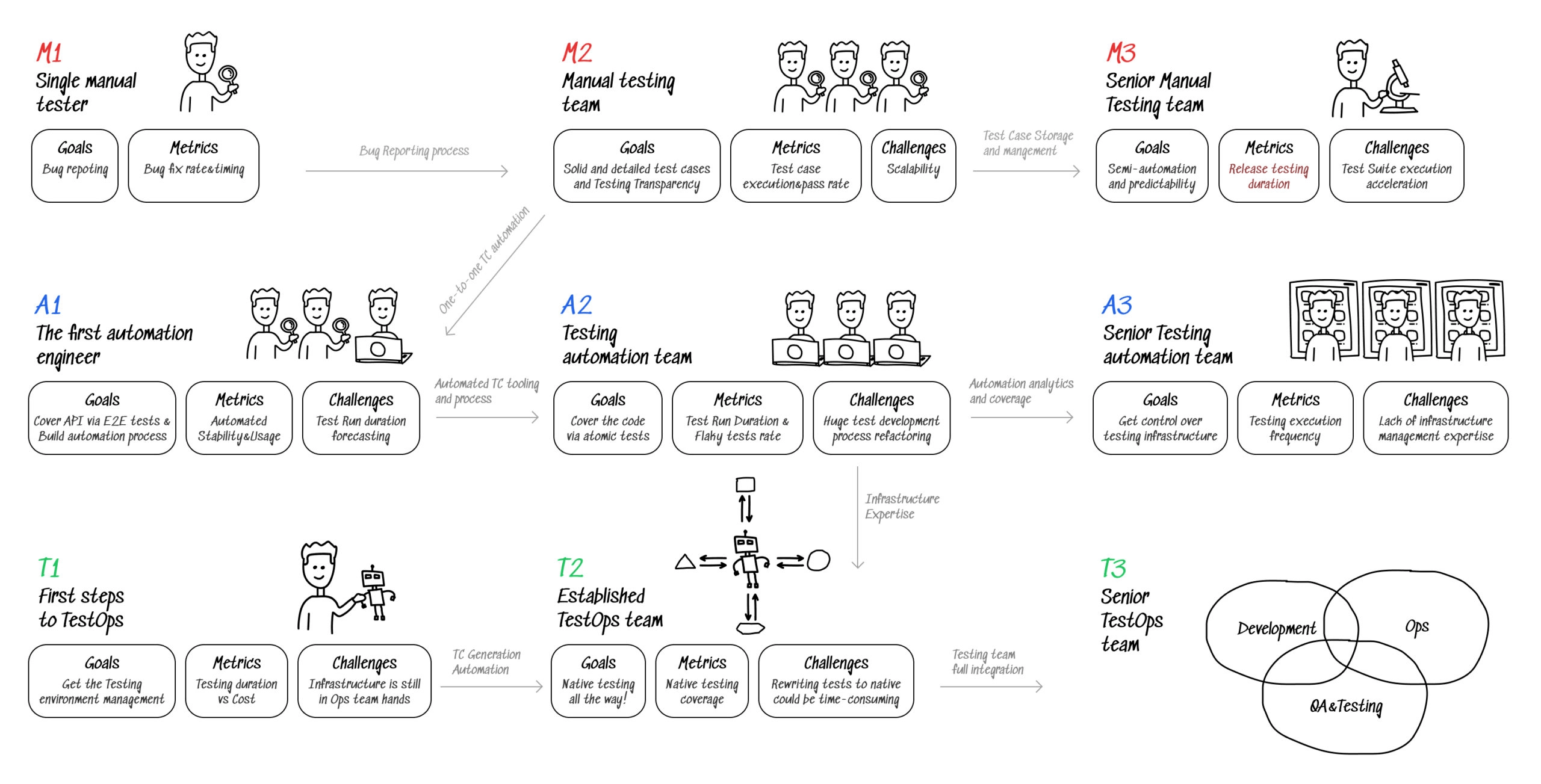
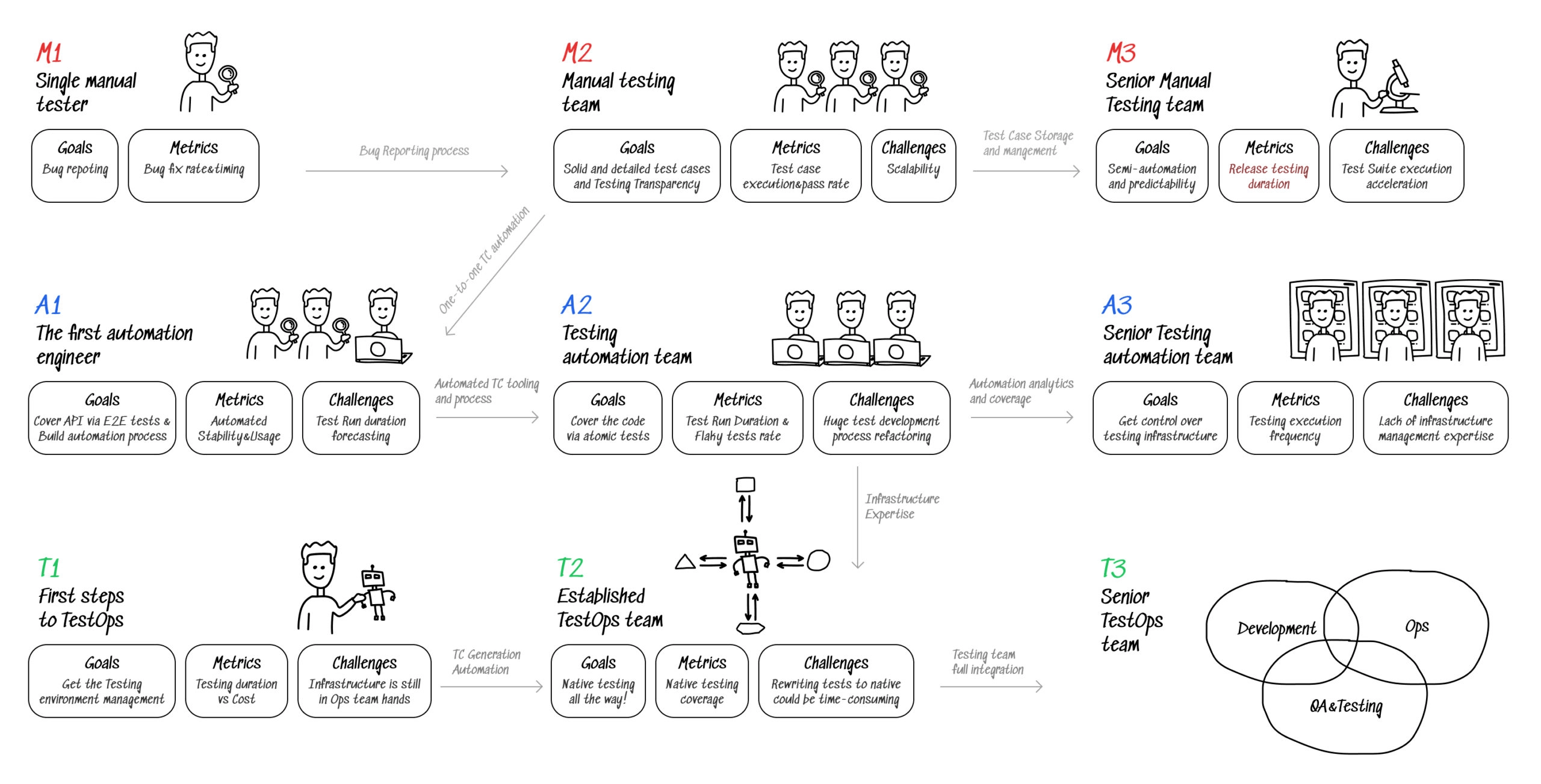
In this article, we will go through all the stages that a QA team evolves through on its path to TestOps, from a startup to an enterprise; and we will try to cover goals, blockers, and tools for each stage.
M1: Single manual tester

The usual starting point for each QA department. Most teams don’t even realize the stage exists, while it often bedrocks the future of QA.
-
Team. Sometimes, there is not even a dedicated QA person at this stage — a product owner or a manager checks everything by themselves.
-
Goals.
- The main goal at this point is to create the bug reporting process. The bug report template will stay for a long time, so take a deep breath and make it as explicit and as easy to fix for the development team as possible.
- The other thing to keep in mind is to keep test cases somewhere. They might be short and lack details; the main idea is to get a rough approximation for the validation testing duration and set the goals for further steps.
-
Tools. Excel, emails, Slack, or any other tools that allow sharing and tracking bug reports. Test cases are usually not documented anywhere except in the tester’s notepad.
-
Metrics. At this early stage, the throughput of your QA department is going to be very low. There will simply be no time to fix all the bugs, so an important measure at this point is defect removal efficiency - the total number of fixed versus the total number of reported bugs. You are setting up bug recording right now, so measuring defect removal efficiency is a good outcome of that. You will want to know how much work is left undone - this would be one of the indicators that it is time to move to the next stage and start increasing throughput.
-
Challenges. When a team is small, it’s always easier to pass the bug directly to a developer and get a fix notification in Slack DM, but this approach will cause chaos in the next stages.
-
Transition point. The team has set up a basic bug detection and fix process.
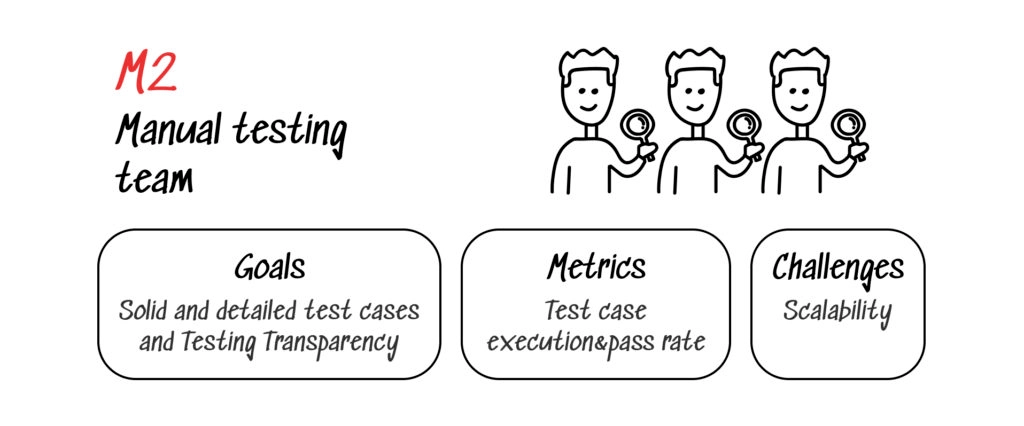
M2: Manual testing team
This is a completely pre-DevOps testing stage where some teams stay for a long time. Especially the teams that don’t aim for fast-paced development processes or project-based ones. The whole idea at this stage is that manual testing works fine for a certain release-cycle pace.
-
Team. Several junior-to-middle QA people with the guidance of a Senior person/ Head of QA.
-
Goals.
- Drop the “I tested that already, let’s deploy!” approach. At this point, you need to set an owner for each test and have a recorded result of a run so that you know who is responsible for a false-green run. Not to punish, but to make constructive retrospectives.
- Testing Transparency. Documentation, pass-failed rates, and linking bugs with issue trackers will make the testing process accessible for the whole team. No one is going to dig into scenarios stored and run in Excel.
- Solid and detailed test cases. That is a part of the Documentation requirement. As you have several people working on a suit, get ready for the situation when a test case drifts from one owner to another. In this case, the test case should contain all the steps, notes, metadata, environment description, etc.
-
Metrics. In the early stages, the team in general might be less interested in quality than in the general viability of the product. They will probably be looking to maximize the effect of the "Aha!" moment and shorten the customer journey map. With the limited resources, the efficiency of QA is going to be paramount, and lead time for changes (the time from accepting the task to deploying the changes) is an excellent metric for that. It will indicate how much the delivery process is limited by testing. As lower-level targets, the QA team might pursue:
- Test case execution frequency. The more often the tests are run, the better. This obviously depends on how much time it takes to run the tests.
- Pass rate. A metric to indicate the quality of the tests. Remember that “all green” might signify test skip errors, not perfect code.
- First reports generation and usage. Try to ensure that the testing results are used by everyone, not just by a manager or a testing team lead. How often do developers look into issues and test cases? Do ops people think manual test suites bring value over smoke suites and canary releases? This is an indicator of transparency, and it will depend in part upon the time it takes to execute tests.
-
Tools. At this point, the team needs a tool to track all the manual testing activity, a TMS basically. The usual functionality is storing and managing test cases, teamwork control, and reporting.
- TestRail, a web-based test case management tool. It is used by testers, developers, and team leads to manage, track, and organize manual testing efforts.
- PractiTest, another amazing end-to-end TMS, provides a lot of team management and reporting functionality for manual testing.
- Qase.io, a modern and rapidly growing TMS to note.
-
Challenge. The speed of testing scales with the labor force only. The larger your regression suite grows, the more people you need to run all the tests on time. The current lack of human resources and experienced engineers makes this challenge even more severe.
-
Transition point. We have well-designed test case storage and team management processes.
M3: Senior Manual Testing team
An optional evolutionary stage that comes as a logical way to develop a team of senior QA engineers. The main idea is to build solid trust in testing across the whole company. Team. Almost the same as in the previous stage. The main difference is the team going senior.
- Goals. Efficiency monitoring and optimization. Manual testing is hard to optimize, but there are many semi-automatic tools to speed up your senior testing team. Remember, that they are bored with routine tasks, so look for ways to automate them.
- Tools. At this stage, tooling solves one and only one task: since we have already built a close-knit team, our task is to decrease the human factor and get as much predictability in testing as possible. Therefore, the team should start looking for tools that automate atomic tester activities like screenshotting, clicking through the test scenario, etc. Let's take a look at some of those tools.
- Postman, a great API-testing tool that allows concentrating on the tests, and not on the execution process.
- FakeData. Manual testing of forms is boring. Using test data generation saves time and eliminates the human factor from form testing.
- LambdaTest and Responsively. Don’t waste time testing multiple browsers with different resolutions. Bots do that much better (and they never get tired!).
- Metrics. Just like at the M2 stage, the most important metric here is lead time for changes. However, the approach is different. By now, QA has well-written documentation and established channels of communication, so process efficiency becomes the focus at this point. The team should get as much as possible out of semi-automatic tools and routine task automation. Along the way, it would also help to measure:
- Release testing duration. This will be part of lead time for changes. It’s important to gain transparency and predictability for each test suite run to be able to estimate the eventual release time.
- Testing effort per release. You could measure the effort of the QA team in e. g. labor hours in order to assess the efficiency of your work. The important thing here is not the specific unit you choose but the direction of change - push it as low as you can. Somewhere along the line, the team will discover that manual testing can only push down lead time so far, and further progress will require automation.
- Challenges.
- Automated testing by the development team (unit tests, integration tests) and the QA team are usually still disconnected.
- Testing process optimization and scaling are still limited by headcount.
- Transition point. Business requires the team to ship releases faster than it seems possible.
A1: The first automation engineer
The first step for a company is to go for automation. Usually, this stage contains basic steps like choosing a testing framework, test execution environments, and coverage metrics. But there is, just like in the M1 step, a huge invisible goal — laying the foundations for further automation development.
-
Team. A team of manual testers gets one middle-to-senior automation QA engineer.
-
Goals. The goals here might look complicated, but they provide a solid base for further development:
- Cover basic APIs with automated e2e tests. A low-hanging fruit to demonstrate how testing automation increases the speed of the whole testing process. A set of UI tests takes more time and effort while being less efficient than a manual set. But a set of API e2e tests with data generation and mocks will cover the routine of a manual team — a great way to get appreciation and support at the beginning of a long automation run.
- Create a process for quick manual test case automation. If possible, the best way here is via automated boilerplate code generation with further tuning.
-
Tools. This stage will require some collaboration between the QA and development teams as an automation QA person will need a testing instance and a CI pipeline for execution. Think about that in advance.
- Testing Environment. Usually, a single E2E testing tool is chosen by the automation engineer. The most common solutions here are Selenium and Playwright. Both tools are great headless browser testing frameworks to start manual test case automation.
- Some sort of IDE, the choice is usually between JetBrains or MS products depending on the chosen tool.
-
Metrics. At this stage, we need to build trust toward automation results, so the metrics will be focused on this goal. The end goal is always keeping the user happy, and faster delivery of features is one benefit of automation that affects the users directly. Measuring customer retention rate and/or churn (percentage of users leaving at the end of the period) could be a good way to know how happy people are with the rate of changes that you provide. There are also lower-level metrics that contribute to this general goal:
- Probably the next most important thing is measuring time saved via automated tests. While the tests are dumb, they are lightning-fast! Automated scenario execution takes far less time than a manual one. That might be obvious, but an explicit measure of time saved with dozens of automated runs is the best way to show the possibility of an order-of-magnitude testing acceleration. Since you've already started measuring testing effort needed for a release, you could adapt it here.
- API tests stability. Automated tests are dumb — this is the first thing the entire team will be bothered with. Even minor changes in the website layout or API response will cause failure. So get ready to focus on tests’ stability and maintainability.
- Automated testing usage. Execute the tests as frequently as possible! Each pull request, merge, and release; in various environments and conditions. The tests won’t bring any value by being idle. No value — no progress.
- Measure manual to automated tests migration rate or automated test coverage. A higher rate indicates automation progress in the long run. A stuck number usually shows a lack of trust in automated tests.
-
Challenges. Though we got our first automated suites at this stage, it’s still almost impossible to predict the time-to-release testing duration.
-
Transition point. The team starts believing in fast release delivery as the process and tooling for automated test case generation are set up.
A2: Testing automation team
In a natural evolution of the previous stage, the team acquires several more automation engineers. This is when up to 60% of automation projects get stuck as there is no obvious way to proceed further. Moreover, the processes from the past stages might bring chaos and conflicts to the evolution of full-stack testing automation.
-
Team. Several middle to senior AQA engineers were accompanied by many junior teammates.
-
Goals.
- Make your software quality system stable:
- Atomic automated tests. Although the long step-by-step tests from the A1 stage seem natural, they bring a lot of downsides and block your team from progressing in the long run. Atomic tests are easier to fix, independent from each other, and provide localized results. That means each failed test provides more precise results and gets fixed fast — mandatory requirements for getting the team’s trust in automated tests.
- Get an interface that anyone can use to run tests. Yes, you need a ‘button’ that runs a test suite, and you want it to be available to everyone. Does a developer want to run tests on their branch? They can do it! Does an Ops person want to explicitly rerun the test suite at a quality gate? No problem.
- Coverage all the way. At this point, the team should go for 100% regression and validation testing coverage. These blocks are perfect for highlighting the value of fully non-manual testing, as they are usually well-documented and consist of easily automated tests.
- Make your software quality system stable:
-
Tools. At this point, our goal is to gain insight from our testing. That means we need reporting and observability tools.
- Reporting tools like Allure Report and ReportPortal. Just as in the M2 stage, be sure to find proper tools to share results and get some control over automated suites’ execution. Both tools are great open-source solutions that age well.
- Full-Stack Testing frameworks: Katalon, Cypress. Choosing a full-stack testing framework is good for teams that plan to stay at A1-A3 levels of testing due to the wide functionality built within proprietary vendor infrastructure.
- Monitoring: setting up a Grafana instance might be a little bit fussy, but it pays back as a universal open-source analytics and interactive visualization tool. Get instant results viewed as charts, graphs, or alerts for your testing.
-
Metrics. By this point, there is more certainty in the appeal of the product and the main feature set. Quality plays an increasingly important role in keeping the users coming back once they've had their "Aha!" moment. As a high-level metric, you can keep measuring customer retention rate. This is ensured by having a high deployment frequency, which becomes possible thanks to a properly automated testing process. Deployment frequency ensures lower time to restore service and resolution time, giving developers and customer support the opportunity to resolve user issues quicker. As lower-level metrics, you can measure:
- Runs / Reruns. The tests must run, pass, and fail all the time. You are the only team to run the tests? It’s a red flag! That means other teams see no value in your tests. Double-check that the Ops team looks at your testing results and runs the suites by themselves on branch merge or release.
- Test run duration. The time itself is not important. Predictability is vital — get an approximate expectation of the test suite runs to show new opportunities for release testing.
- Percentage of flaky tests. Sometimes tests start being funny and get passed-failed results in several consecutive runs for no obvious reason. Such tests should be isolated, investigated, and fixed, depending on the reason for their flakiness, be it infrastructure issues or poorly written tests.
- Time-to-fix for a broken test. The team will get broken tests eventually. Doesn't matter if the reason was a change in business logic or the test itself. What is important is how fast we can fix a broken test. If it takes a lot of time, nobody will wait for us, so we’ll lose the trust of the team.
-
Challenges.
- Testing infrastructure usually stays out of reach of the QA team. This constraint leads to an inability to influence the execution time and amount of runs/reruns of test suites. This is the trigger to keep developing the QA infrastructure.
- Change the manual testers’ workflow. As your tests get more atomic, you’ll see that mapping large manual test cases to a set of atomic automated tests is a blocker. Using checklists for manual testing instead is a better solution.
-
Transition point.
- Full regression and validation testing automation. As soon as these types of testing are fully covered with automation, the team gets enough time to think about further infrastructure development.
- Testing results gathering and reporting automation. Another type of work that requires lots of time and effort with automated testing.
A3: Senior Testing automation team
The senior Testing automation team is born when the testing team aims to get full access to the DevOps pipelines and testing infrastructure while becoming extremely skilled in testing itself.
-
Team. 10+ senior AQA engineers’ team.
-
Goals. Get your hands-on testing infrastructure. Testing is not just writing tests — it's also gaining control over testing infrastructure; the QA team needs to stay in touch with the Ops team. Leave the hardware and script-level maintenance to the Ops team while striving to gain control over the basic testing environment configuration. Why do we need this control? Because different teams care for different things: the Ops team usually cares about low-level stuff like caches, build scripts, or database accessibility, while the testing team works on minor tweaks and performance analysis, dependencies, data, and environment updates. That is a must-have requirement for the team to integrate into the main DevOps pipeline. Lower timing allows for fast and precise testing of each branch and release — the main goal of the A3, the final point of a separate testing automation team.
-
Tools.
- Allure TestOps, as a full-stack testing automation solution, provides the testing team with several must-have features out of the box:
- Testing Tools integrations, be it JS, Python, or Java testing framework or some full-stack tool like Playwright / Selenium.
- Control over the CI/CD system that allows running custom suites, rerunning selected tests, or storing the history of runs.
- Detailed analytics and automated fail investigation.
- qTest, another large-scale test management tool for agile testing. It follows the centralized test management concept that helps to communicate easily and assists in the rapid development of tasks across the QA team and other stakeholders.
- Allure TestOps, as a full-stack testing automation solution, provides the testing team with several must-have features out of the box:
-
Metrics. At this point, we should focus on test execution frequency. This is related to deployment frequency, which we're already measuring, but there is an important difference in attitude. We need to put the effort into maximizing the usage of tests by the whole team: developers, Ops, testers, and sometimes even management folks. Testing has to become a tool for the whole team.
-
Challenges. The main challenge here is the lack of infrastructure management expertise. Going for this stage definitely requires you to make sure your QA and Ops teams are coherent: learning DevOps basics and infrastructure management will demand a lot of collaboration. Remember, different teams care about different things: if you don’t dig into the infrastructure, your Ops-related tasks (updating Selenium or a framework, for example) will likely be postponed to the last.
T1: First steps to TestOps
The first TestOps stage means the QA team steps out of the testing bubble and integrates into the main development pipeline flow. At this stage, we already have our codebase well-covered by neat and atomic automated tests that run semi-automatically on the main pipeline. Now, our focus moves to get prepared for full-scale integration with Ops.
- Team. The main difference in terms of the team is that Ops-expertise is spreading among the testers. We’ll need two or three folks familiar with server administration and CI/CD tools and processes.
- Goals.
- Getting responsible for all the testing infrastructure. Get used to maintaining all the emulators, Selenium instances, and other testing stuff with your team of administrators: start updating browsers or Docker on the testing server. It’s important to be backed up by an experienced admin.
- Remember the ‘run tests’ button we got at A2? It’s time to get our hands on it. We have to integrate our testing servers into the main development pipeline while being responsible for them. As soon as you are responsible for the infrastructure, you won’t get those tricky fails and flaky tests due to “scheduled” testing, a DB wipe, or a Selenium configuration update. Also, you’ll be able to quickly fix all the issues by yourself!
- Automate more! Start setting up testing notifications, and ask the Ops team to monitor the test execution.
- Tools. At this stage, we need the tools to build a scalable and flexible automated testing infrastructure.
- Docker, to easily manage and run multiple environments. Create several presets and keep them running on demand.
- Jenkins, an oldie but goodie. Jenkins is not the easiest system to set up, but it keeps being recommended because of its huge open-source community and rich ecosystem.
- Metrics. During the automation stages, we've been more concerned with velocity metrics, such as deployment frequency and lead time for changes. Now, as the product is scaling up, the cost of mistakes goes way up as well. This means two things. First, metrics of stability become more important. Both mean time to restore service and change failure rate are important for assessing user experience. Second, we need to start measuring the costs of testing vs not testing.
- Test Suite execution duration vs Costs. As soon as we get our voice louder, we can optimize the metrics that involve the Ops team’s job. If your pipeline gets stuck on testing Quality Gate, ask for more power! But remember to stay within the estimated budget.
- Cost of downtime. Combined with mean time to restore service and change failure rate, the cost of downtime will tell us how much we are losing due to defects that have escaped our QA process. Comparing this with the cost of testing tells us whether we should invest more in QA.
- Challenges. As in the A2 stage, we get more control over testing infrastructure, but the metric stays out of our direct influence. Remember to keep close contact with the Ops team, as their experience is something that will let us reach the T1-T2 transition point.
- Transition point. As soon as we get used to the fact that we are in charge of the pipeline and all suits run like clockwork with notifications, automatically generated reports, and so on, we are ready to go!
T2: Established TestOps team
Testers and developers should start writing tests together on the same tech stacks. This stage is necessary to break the silo mentality between testing and developers. Test infrastructure management on testers and ops provides pipelines to quickly streamline the new feature to market.
-
Team. A team of senior testers turns into a team of SDETs with experience in Ops and infrastructure maintenance.
-
Tools.
- GitHub / GitLab. We’ll need a code-based collaboration tool, and I am not sure we can advise anything over GitHub.
- Allure TestOps, as a tool that will keep all the testing open to non-development people. Features like live documentation will automatically keep track of what’s tested and testing fail/pass rates. Advanced dashboards will let the team aggregate full-stack testing analytics that will include testing at all levels: developers testing, ops testing, and QA testing, of course.
-
Goals.
- Migration to native testing tools. Native means that tests use the same tech stack as the code they test. Here's the neat part — they can also be stored in the same repo as the code they test. Here are some examples:
- JEST for JS
- XCtest for iOS
- Kaspresso for Android
- Pytest for python
- JUnit5 for Java or SpringTest for Spring.
- Developers write low (unit) and middle (integration) level tests. Testers at this stage should start reviewing these tests for two reasons: improve the quality of the test with QA best practices and learn better coding patterns from developers. Since all the testing now lives in a single repository, that process is easy to implement.
- Migration to native testing tools. Native means that tests use the same tech stack as the code they test. Here's the neat part — they can also be stored in the same repo as the code they test. Here are some examples:
-
Metrics. Test automation was about pushing efficiency to the limits; TestOps builds upon this by making the process fully controllable and transparent. As a result, detection of bugs should shift to much earlier stages in the pipeline, ensuring a very low change failure rate. Keeping track of this metric will give you an overall picture of how effective your TestOps migration is - along with the other stability metric, mean time to restore service. For a more direct measurement, you could track native testing coverage and migration pace. Remember the description of the DevOps-native testing flow? Infrastructure and processes are covered at this stage, so the only thing to improve is native testing rates.
-
Challenges. Native testing requires more programming skills from the testing team than before. The best way to learn the skills is to work closer with dev people. The challenge here is building bridges and cross-functional processes to achieve our goals.
-
Transition point. As soon as we migrate our “legacy” testing to native, we are all set to move to T3, which was actually described in the "How does the DevOps-native testing look like?" section!
In conclusion
Of course, you may run into pitfalls not included in this post at each stage. However, we have tried to outline both the most important paths to development and the main causes of deadlocks. Stay tuned for other posts to discuss the most difficult stages in detail.