QA metrics for DevOps: how to make them work
Playing with numbers is fun, but collecting metrics can be a complicated process that will take up your time and energy. Here, we'll take a look at some of the potential pitfalls on the road to building a meaningful metric.
QA metrics for DevOps: how to make them work
Metrics are strange things: it might seem like they don’t cost anything, but they do. QA metrics are no exception. Gathering them requires work and infrastructure. They have to be maintained. And if a metric carries an actual, measurable cost with it, its existence can only be justified when it provides an actual, measurable benefit. The metric should allow us to make decisions that will result in a net benefit for the team and the company.
Say we’ve counted the number of bugs that emerged in production. What next? Sure, having 0 bugs would be awesome, but what does that number tell us about how we should distribute our effort? In and of itself - nothing, which means that the cost of gathering that metric is not offset by any benefit.
However, it’s not like we can just start measuring money everywhere. That would be a very superficial view of business needs. How do we relate metrics to those needs in a way that allows us to make technical decisions?
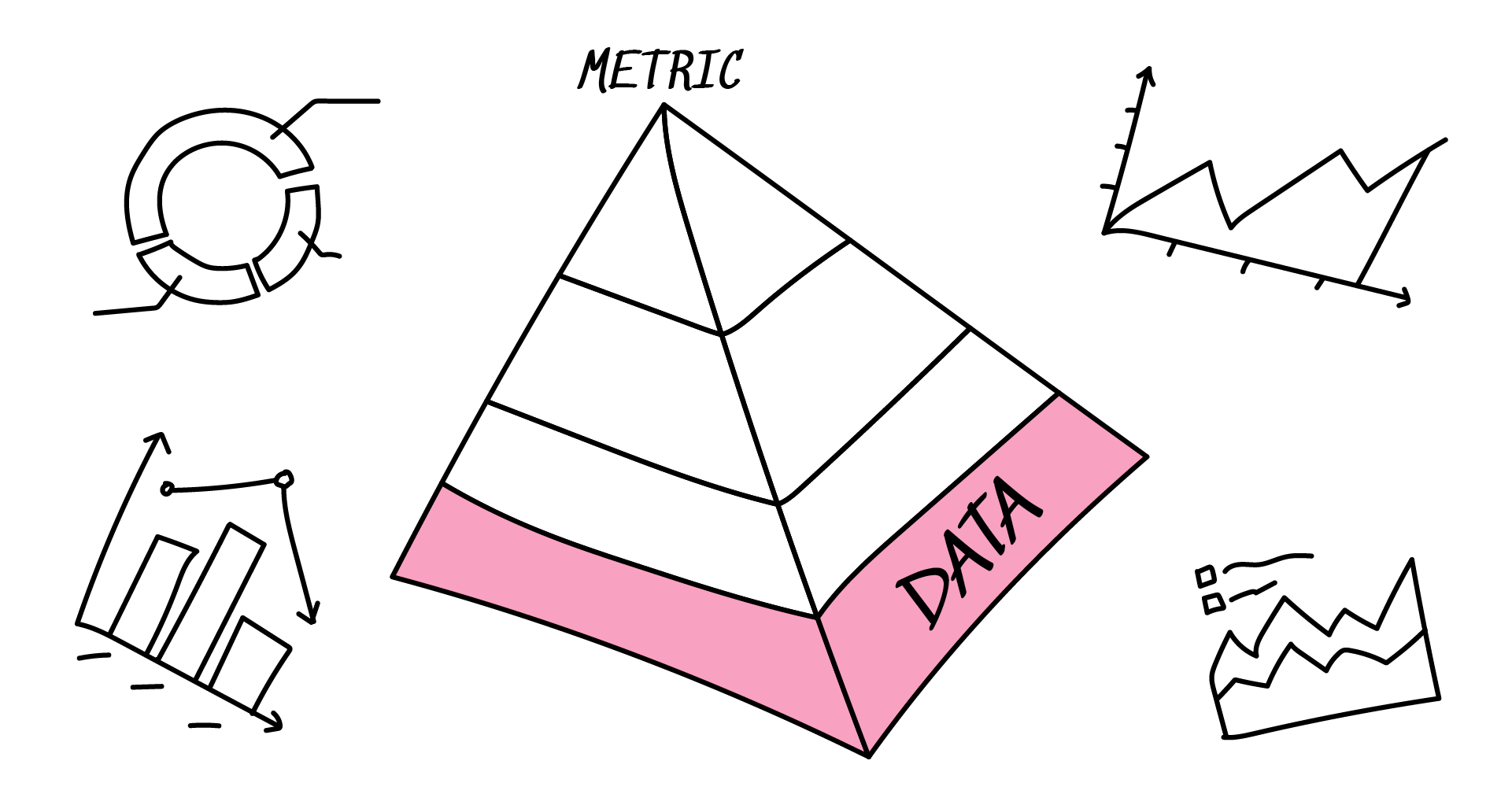
If you would like to know how we’d like to tackle this question with specific metrics, we’ll have more articles about that later (like the one we’ve already published). Here, let’s try something more general. Let’s think of a pyramid of problems, where each layer rests upon those below. Starting with the top, here’s what we’ll be dealing with:
- What are we creating a metric for?
- What is the scope of the metric going to be?
- Who’s going to use the metric?
- Last but not least: how is the data going to be gathered?
If something goes wrong at the bottom, the whole thing will crumble. If something is wrong at the top, the edges of the pyramid won’t meet and all the effort will be wasted.
What is the metric for?
The goal of QA is not to find all the bugs imaginable, but to provide a competitive advantage for the business. This can be achieved by improving user happiness and team efficiency - of all teams, not just QA.
The bottom line of any business in IT is the user, and in the end, user happiness determines whether the product will sink or swim. However, user happiness ostensibly has to be the headache of marketing, or someone dealing with user experience. We’re just dealing with technical problems, right?
In reality, things are more complicated. It’s all about the distribution of effort. Different technical problems have different impacts, and user happiness determines the severity of the problem.
Let’s take a look at a familiar example. Measuring code coverage has become quite popular at a certain point, and it has been fashionable to shoot for 80% or even 100% code coverage. And yet, what, specifically, does this number give us? You don’t write code to run it once and only once. The number of pathways that execution can take is immense. We’ve got to prioritize which paths to spend our limited time and effort on. And here, code coverage provides no help.
What does help? Well, software requirements express what that software should do for the user; so why not measure requirement coverage? In this case, gathering data is somewhat trickier than with code coverage, but once you’ve hit your mark you’ve got much more certainty that your tests provide value.
Still, not all requirements are equal, and time and hardware are always constrained. This is why when working with requirements it’s a good idea to prioritize them. Testing login and registration need to be done much more thoroughly than adding something to favorites. One could even take this a step further, assign risks to each of your requirements, and calculate risk coverage. This is probably taking things a bit too far, but even simple prioritization is very helpful, so that we can focus on things that matter the most for the user.
The point is for you to be able to efficiently distribute your resources and reduce the size of your test base while maintaining its effectiveness. The number of tests being run had often been considered to be an unambiguously good thing - until people started realizing that fitting large test runs into tight delivery cycles meant either spending more time doing tests or spending more money on hardware. In addition, tests require maintenance, since the code base always changes and the tests have to keep up. And cutting down the size of the test base means prioritizing.
Summary: aim
A metric that pushes you to test everything expends your effort and bloats your test base, slowing down delivery and requiring maintenance and hardware expenditure. Cutting down on those costs requires prioritizing. And this is only possible if the metrics we’re using are aligned with real-world goals, the first of which is user happiness.
What is the scope of the metric?
We’ve figured out what our endgame is - user happiness and team efficiency. But that tells us very little if we don’t know how to affect those things. We need to measure something that we can control. Our metrics need to have a specific scope, a context. Without it, the values will be meaningless.
Can’t judge value without context
Let’s start with the fact that averages are very bad at measuring stuff that has a lot of variation. You might have several teams, each of whom works on separate products. One might take an average of 5 minutes to close a task, another might take 60, and a third one - 120. It would make no sense to calculate the overall average because the situation is too different for each team - just segment the data and look at it on the team level.
So, context tells you if the value you’re seeing is high or low. Say you’ve taken your measurements, and then you get stuck looking at a number: is 80% coverage good or bad? Or: we’ve found 20 bugs. Is that a lot? You need something to compare the number to, and that can be as simple as just comparing the number of bugs to the number of tasks they’re related to. Our response will be very different with 2 tasks and 40 tasks. And you might not even need to calculate some ratio and create an additional metric - and thus additional noise. If you’re in the QA team and you know the situation, it’s enough to just have the two numbers next to each other.
Let’s take another example. A task was bounced back to developers 5 times after it’s been created. Is that a lot? Depends on how long it took for the developer to react each time. It might have taken them 5 seconds or 5 weeks. We need to know that if we are to decide whether to speed up our process.
Putting numbers against each other
For most decisions, you are going to need more than just one figure. If you’re looking at a graph that is telling you that automated test coverage is up 5% one sprint and down 5% the next sprint, that in and of itself tells you nothing. You’ve got to push on the data repeatedly and drill down. Collect a history of values, and build and test hypotheses about these values. And if you are a team lead, don’t isolate other members from this work. Get feedback from them, and try making sense of the numbers together.
Creating a key metric
With the gathered data it should ideally be possible to create a meaningful metric that would serve as a quality gate. The other figures will still be there to provide context if you need to drill down and figure out what's going wrong.
We started this section by saying that usually, how we judge the value of a metric is determined by context. But if we are to create a key metric that could serve as a standard, it should be the other way round: its values should inform us about what our context is. This means that not all metrics can be used this way. Usually, this would be an industry standard the values for which have known consequences.
Let's look at an example of such a key metric. If we see a figure of 20% failed tests, we know that on every run, the AQA engineers have to sort through all those test cases - instead of writing new tests. If, on the other hand, we've got only 1% of failed tests on a run, we know that the tests are stable, the software doesn't undergo radical changes, and most likely we've got a proper testing strategy.
Of course, it still might be the case that your 1% figure is explained by the fact that you're simply not running the tests on each commit. Even higher level, key metrics need other figures to support them. But drawing conclusions from them can be done more reliably.
Summary: scope
So here is the challenge. The only useful figures are the ones that you control and whose context you understand. But they still have to be tied to user happiness and general team performance if they are to provide value. This means that most likely you will end up with several metrics that provide context for each other, and among them, you will have an overarching metric that ties you to business goals - like a North Star.
Who uses the metric?
We now know what a metric is for and what makes it valid. Time for the next question: who is using that metric? Are they used for decision-making and analysis, or are they used as targets?
A metric might be used by:
- The test lead. If the QA team is small enough - say, under 4-5 people - it might not need any metrics at all. At this stage, everyone has a pretty good idea of what everyone else is doing, and everything is coordinated by a senior tester. As the team is growing, there appears a person who is responsible for everyone else’s work - a test lead. And they are the ones who’ll need metrics the most, because they will need visibility into what everybody is doing.
- The rest of the team. Other members should not be shut out. It’s a good idea to have the metrics open to the entire team so that everyone can use them. E. g. tracking how much it takes to finish a task on average is probably something that everyone would like to know. And apart from the team metrics, there are also personal metrics, which people can use to track their own progress. As long as this isn’t being used to shame people, this can be very productive - the team can help the person figure out the problem and catch up.
- The managers. Metrics are used on every level of the management structure, and usually, they are composites of those that are used below. The atomic metrics (e. g. CPU load or cluster status) are probably tracked at the team level and are fairly hard to misinterpret. However, when they are combined into a composite metric, there is always room for presenting the world slightly better than it actually is. For instance, when calculating success rate, a flaky test with 3 green runs out of 5 might be counted towards the total, whereas in fact, such a test still needs work. Here, the solution is the one we’ve already discussed above. The more you judge a metric against other metrics, the less they can lie about each other. You can report that you’ve got zero flaky tests, and that’s going to sound wonderful until you also report that you’ve run those tests zero times.
Metrics as targets
Using a metric as a target is a very straightforward way of getting value from it, but it doesn’t always work as intended (this is known as Goodhart’s law). So when does it work and when does it not?
Setting targets for sprints is perfectly normal, but what about more general KPIs? Here, it depends on how stable the business processes are. If we’re talking about an enterprise setting where all the processes are inside the company and development works like a proper assembly line - sure, KPIs might be a good idea. But usually, there is a lot of uncertainty about what we’re testing, what bugs there are, or how much time testing will take. And in this case, KPIs make very little sense, because too many things are outside QA’s control.
Summary: consumer
Thus we have two main dangers. In a traditional QA team, there is a tendency to focus on measurements that do not take into account business interests; on the other hand, managers might focus on metrics that present a somewhat rosy picture of what’s going on. This is something we should take into account when building our metric. The solutions here are: aligning metrics with real-world goals and checking metrics against each other.
How is the data gathered?
Finally, you need to determine how much work you will need to put in to gather the metric. Any metric requires annotations, tags, etc., and triggered events based on that markup. If you’re lucky, this might be provided by the tools you’re using. But the truth is that right now, most TMS provide only the simplest tags out-of-the-box (test case, launch, author). You might set up a system like Metabase that will gather data for managers - but that is a separate project all on its own. Very likely, you’ll end up setting up a custom solution to gather data. All of this illustrates the main point: metrics have a cost.
Let’s say you’re trying to gather data in a TMS on how much time a task is getting tested on average. You can look up the time inside each task manually, but does that really sound like a good solution? Alternatively, you might write your own parser, use webhooks, or write requests to an API or a database. This means writing code - something that manual testers probably won’t be doing. Instead, it will probably end up the job of someone with a more specialized skill set - like an SDET (software development engineer in test) or a productivity engineer.
Gathering metrics by hand or writing custom code probably means that data will be stored in multiple places. This makes it more difficult to access; likely, only the test lead will be working with all the sources. This means that other team members will be asking them to provide data. All of this means more workload for the test lead.
Collecting data for a metric will often require the cooperation of other teams outside QA. Say you’re adding tags to your tasks to make bug tracking more informative. Some of the tasks will be created post-release by tech support; some might be created by the development team. Both those teams will have to be convinced to join in with adding tags, so they will need to be explained that everyone will profit from this activity. This communication will probably go well if everyone is reasonable - but what if they’re not?
With manual tests, gathering data takes even more effort. Also, some of it is going to have to be gathered by hand - which means errors are much more likely. E. g. a tester might have to record the time at which the test started and whether or not the test passed, and they could set the wrong flag by mistake, or forget to set any.
If the tests are automated, the process becomes smoother - but it’s still not happening for free. If automated tests are run locally, gathering data will present challenges. In addition, the metrics are affected by the environment - the same test will take varying time to complete depending on the system where it’s being run. If the metrics are to be informative, the tests should preferably be run remotely, on a CI/CD server.
In an ideal world, data gathering should be automated and data storage - centralized. As an example, Allure TestOps provides such centralized storage. This would significantly reduce the cost of gathering and accessing metrics - although they would still not be completely free.
Summary: data
Gathering data and maintaining a metric requires resources. There are ways to limit those costs - e. g. if your testing is mostly automated it becomes much easier to get the needed signals from it and automate the metric itself. Having a centralized storage for data is also a very good step towards making it more accessible and maintainable. But neither of those steps makes data completely free.
Summary
The problems we’ve been talking about have specific organizational reasons. In a team that is broken up into silos, QA tends to become isolated. Testing is done for the sake of testing, not to pursue business goals. And because of that, metrics that are used in such a QA department are usually not connected to the product and the user. We’ve already written a guide on how to break this isolation of QA.
This situation has persisted for a while, and it might be related to the fact that business processes in IT are much less stable and controllable than in e.g. manufacturing. Today, there is a trend to reverse this state of affairs. People are trying to bring QA “back into the fold”, and integrate it with the rest of the software delivery process. Figuring out how to deal with metrics in QA is a part of that process.
We’ve seen that the end goal of metrics is affecting something in the real world, where the product is being used. It might be user happiness, or it might be the efficiency with which user needs are served. But for the metrics to be effective, their scope has to be within the team that uses them. Also, metrics should be in the hands of those who can make meaningful decisions with them. And finally, deciding whether or not to use a metric will depend on the cost of digging for data - whether it’s provided out-of-the-box or we should gather it on our own; whether the process is automated or done by hand. All of this should factor into the decision of whether or not to use the metric.
We'll be back with more metrics!
This is an important and complex issue, and this article is intended as an overview of the problems that we want to write about. We'll be digging further into specific metrics and will also explore various use cases. All the interesting stuff that we'll find will be shared here, on this blog, so stay tuned!